Introduction
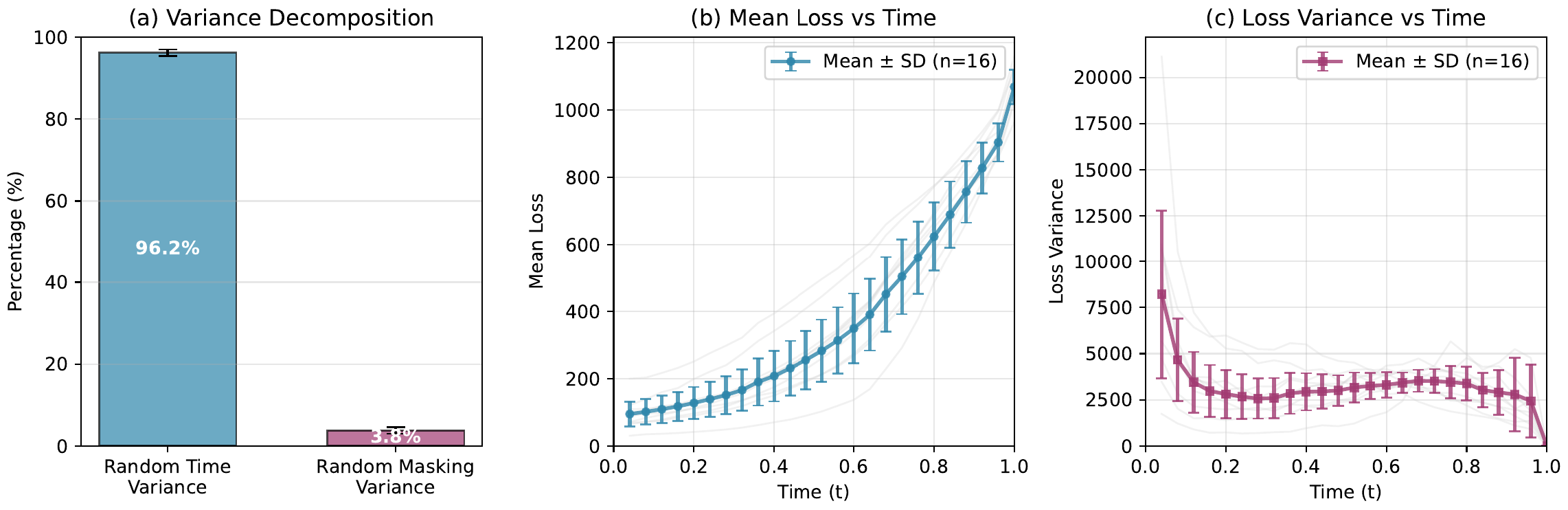
There has been an ongoing effort to adapt reinforcement learning (RL) algorithms for LLMs to DLMs. Most works have considered extending GRPO by finding ways to approximate the token-level likelihoods. However, this approach often comes with significant biases or computational inefficiencies. A more principled foundation lies in sequence-level likelihoods, where the ELBO serves as a surrogate. Yet, despite this clean mathematical connection, ELBO-based methods have seen limited adoption due to the prohibitive cost of likelihood evaluation.
In this work, we present efficient ways to estimate the ELBO for DLMs and leverage it to improve reasoning for DLMs. We introduce Group Diffusion Policy Optimization (GDPO), a new RL algorithm tailored for DLMs that leverages these efficient ELBO approximations to improve reasoning for DLMs. Our work leads to new SOTA results in finetuning LLada!
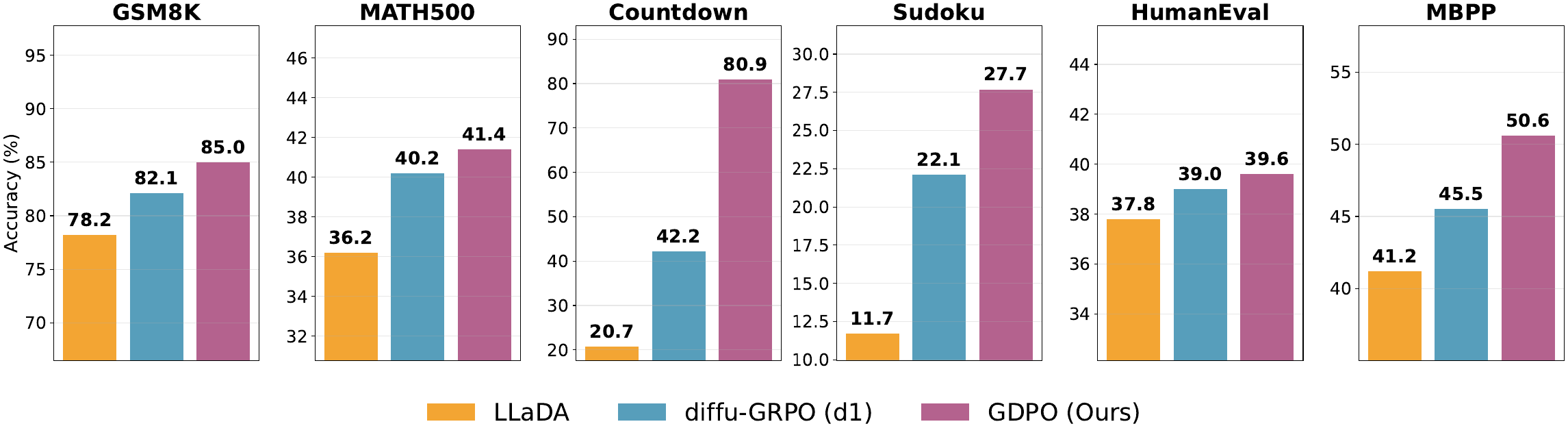
GDPO achieves new SOTA results in finetuning LLada on a variety of reasoning tasks.